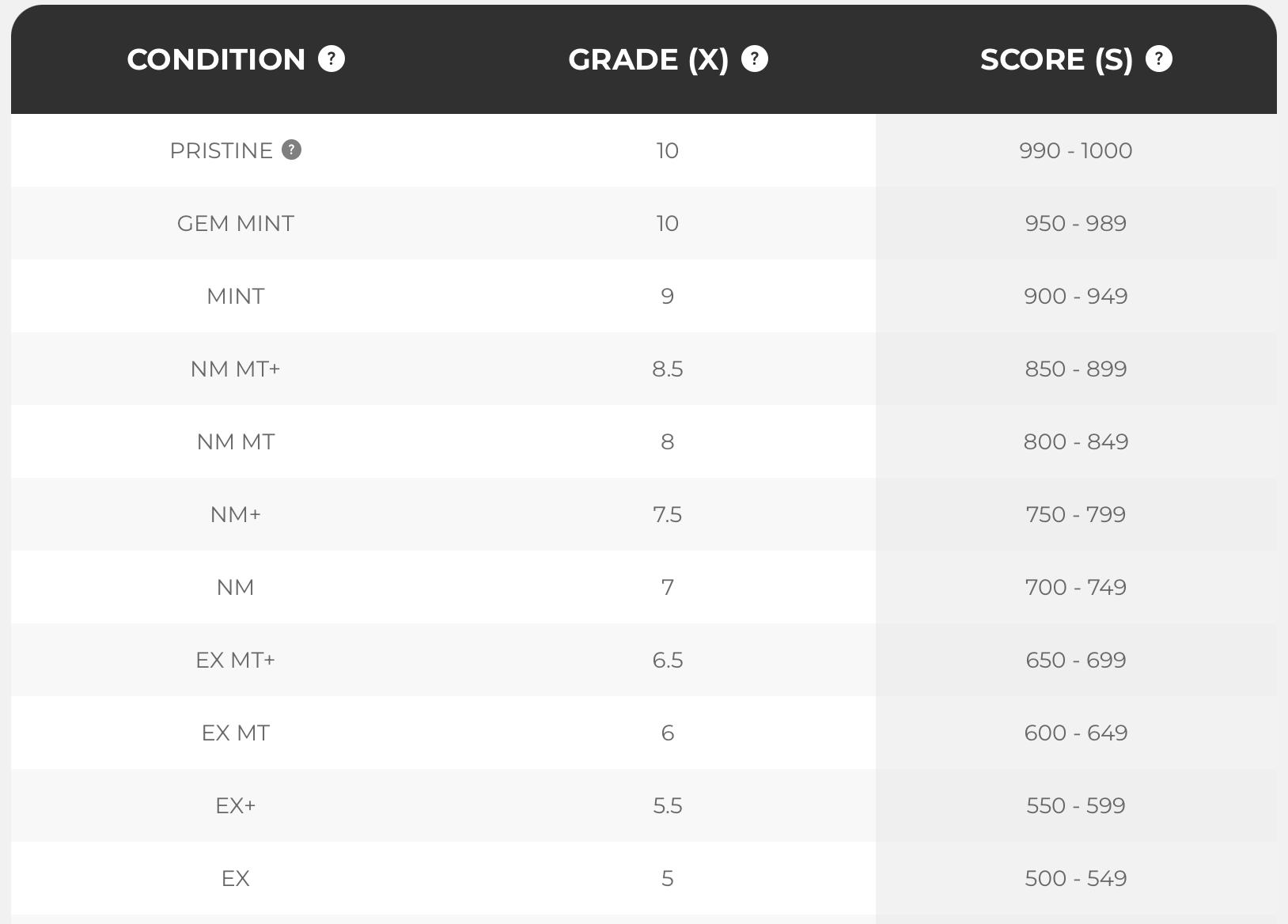
No offense but you still havent explained at all why there would be any variation for tags system
949 is just an arbitrary number for them
What matters is that unless the instruments were obstructed and the the ai couldnt “see” the same thing, there is no reason why it wouldnt just 949 again and again
Every image it takes is associated with a specific and deadly consistent way to understand and interpret what its seeing and translating it into a score
This literally will not change.
It works within a rule set. If the instruments see the same exact thing, the same rules will trigger
You saying “a 949 looks like a 950” yes thats how a human would look at things, not a computer
The models would have to change. The data of how to treat a specific flaw would have to be updated
Thats literally the only way it could give variation
Could tag be wrong in its grade? Yes
Absolutely yes
Thats why i shop tag misgraded slabs to crack and sub to different grading companies
For instance tags system was suggesting that there was a surface defect on the holo pattern of a japanese base set card, but in reality it was just a sporadic holo pattern that appeared stacked cosmos
But i get it, not many japanese base cards with crazy cosmos patterns have been graded through tag so their isnt enough training being done with this type of card for it to understand what to do with what it sees as an anomaly
So the card was dinged for a surface flaw and scored a tag 5
It was dinged hard for the surface flaw but a human grader wouldnt see an issue with it
So can it be inaccurate?
Yes
But what matters is that its consistently inaccurate
Unless the models changed, tags system would pick it up as a surface flaw over and over and ding it the same way
But so long as the instruments show the same images each time, the calculations and inferences made will be exactly the same.
And you haven’t demonstrated one time, even remotely, how or why that would not be the case.
So respectfully, i will just assume its because you dont have a real argument at all